COMP20003 - Assignment 2 : Spellcheck Lookup
Your Task


Assignment:
Overall, you will create a partial error-handling dictionary (spellchecker) using a radix tree.
You will be using the same dataset as Assignment 1.
Users will be able to query the radix tree and will get either the expected key, or the closest recommended key.
You will then write a report to analyse the time and memory complexity of your Assignment 1 linked list compared to your radix tree implementation.
C Implementation:
Your programs will build the dictionary by reading data from a file. They will insert each suburb into the dictionary (either the linked list (Stage 3) or radix tree (Stage 4)).
Your programs will handle the search for keys. There are three situations that your programs must handle:
Handle exact matches: output all records that match the key (Stage 3 and 4).
Handle similar matches: if there are no exact matches, find the most similar key and output its associated records (Stage 4 only).
Handle no matches being found: if neither exact nor similar matches are found, indicate that there is no match or recommendation (Stage 3 and 4).
Your programs should also be able to populate and query the dictionary with the Assignment 1 linked list approach and the radix tree approach.
Your programs should also provide enough information to compare the efficiency of the linked list with the radix tree with a operation-based measure that ignores less important run-time factors (e.g. comparison count).
Assignment:
Overall, you will create a partial error-handling dictionary (spellchecker) using a radix tree.
You will be using the same dataset as Assignment 1.
Users will be able to query the radix tree and will get either the expected key, or the closest recommended key.
You will then write a report to analyse the time and memory complexity of your Assignment 1 linked list compared to your radix tree implementation.
C Implementation:
Your programs will build the dictionary by reading data from a file. They will insert each suburb into the dictionary (either the linked list (Stage 3) or radix tree (Stage 4)).
Your programs will handle the search for keys. There are three situations that your programs must handle:
Handle exact matches: output all records that match the key (Stage 3 and 4).
Handle similar matches: if there are no exact matches, find the most similar key and output its associated records (Stage 4 only).
Handle no matches being found: if neither exact nor similar matches are found, indicate that there is no match or recommendation (Stage 3 and 4).
Your programs should also be able to populate and query the dictionary with the Assignment 1 linked list approach and the radix tree approach.
Your programs should also provide enough information to compare the efficiency of the linked list with the radix tree with a operation-based measure that ignores less important run-time factors (e.g. comparison count).
An Introduction to Tries and Radix Trees
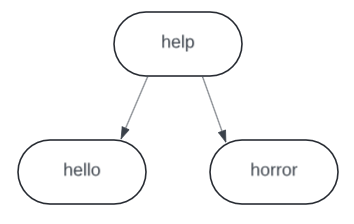
First, it is important to establish the difference between a Trie and a Tree. This is best illustrated with an example. One example of a tree is a binary search tree (BST), where each node in the tree stores an entire string, as illustrated below. The nodes are ordered and allow easy searching. When searching in the BST, we compare the query with the entire string at each node, deciding whether to switch to the left or right subtree or stop (if the subtree is empty) based on the result of the comparison.
A trie is slightly different. It has multiple names, such as retrieval tree or prefix tree. In a trie, the traversal of the tree determines the corresponding key. For the same strings as above with one letter per node, it would look like:
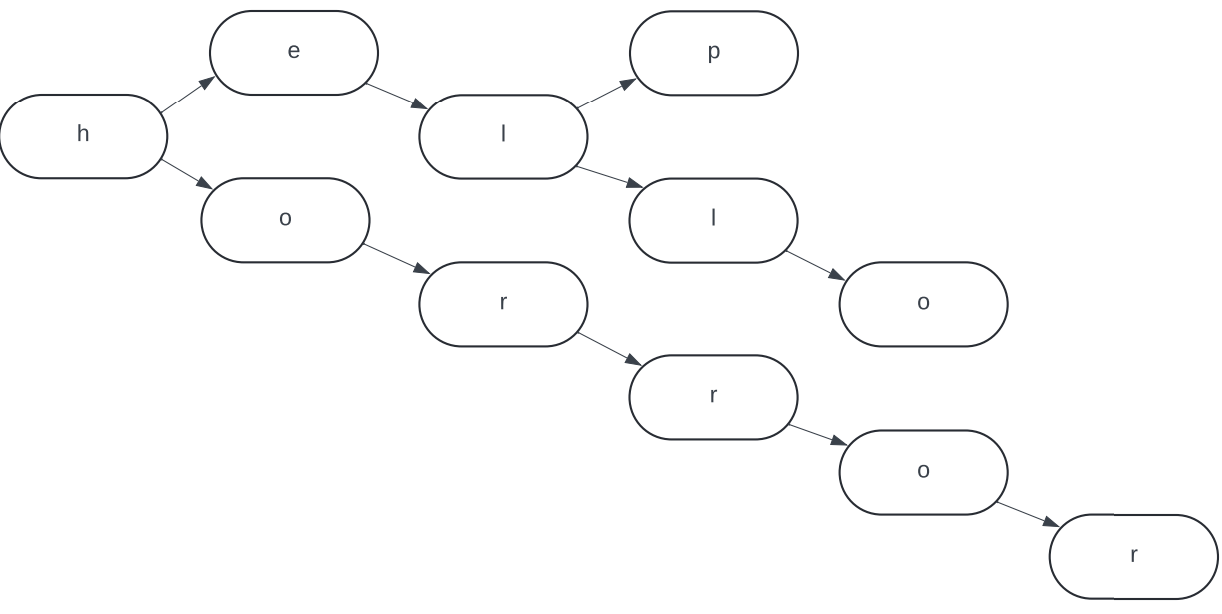
Tries allow for quick lookup of strings. Querying this trie with the key "hey" would find no valid path after the "e" node. Therefore, you can determine that the key "hey" does not exist in this trie.
A radix trie is a subtype of trie, sometimes called a compressed trie. Radix trees do not store a single letter at each node, but compress multiple letters into a single node to save space. At the character level, it would look like this:
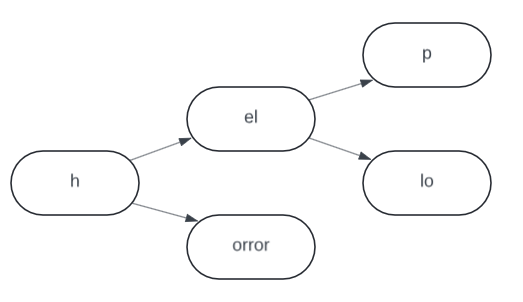
Radix tries can again be broken down into different types depending on how many bits are used to define the branching factor. In this case, we are using a radix (r) of 2, which means every node has 2 children. This is accomplished by using 1 bit of precision, so each branch would be either a 0 or 1. This type of radix trie (with r=2) is called a Patricia trie. Another example of a radix trie with r=4 would have 4 children, determined by the binary numbers 00, 01, 10, 11. The radix is related to the binary precision by r = 2x where x is the number of bits used for branching.
Radix trees benefit from less memory usage and quicker search times when compared to a regular trie.
While these visual representations are at the character level, a Patricia trie is implemented using the binary of each character. Each node in the trie stores the binary prefix at the current node, rather than the character prefix. For example, we can insert 3 binary numbers into a PATRICIA trie: 0000, 0010 and 0011.
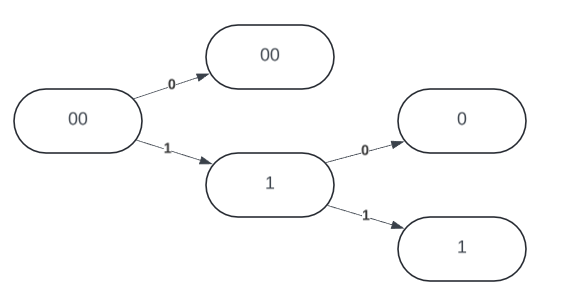
Combining the previous worded example with the binary representation gives us a patricia tree of the form:

You should trace along each path and validate that the stored strings are the same as the example above. Each character is represented over 8 bits, and the last character is followed by an end of string 00000000 8 bit character, i.e. NULL.
It is important to note that these representations only show the prefix at each node. An actual implementation will require more information within a node struct. To see this, look at the "extra insertion example" slide.
Implementation Tips
To implement the Radix Tree, a recommended approach is to use the functions provided below.
Get a particular bit from a given character
getBit(key, n)andExtract a stem from a given key
splitStem(key, start, length)which extracts a certain number of bits from a given key.
If you want to understand the code provided, you need to understand the following bit operators over numbers a and b:
Implementation Details
Assignment 2 will involve roughly three new stages.
Stage 3 will extend your Assignment 1 solution to count the number of comparisons it takes to find a given key, i.e. a search query.
Stage 4 will implement the lookup of data by a given key (Official Name Suburb) in a Patricia tree.
Stage 5 is a report about the complexity of a linked list compared to the Patricia tree.
Stage 3: Linked List Search Comparisons
In this stage, you will extend your Assignment 1 solution to count the number of binary and string comparisons and node accesses used when searching for a given key.
Your Makefile will produce an executable called dict3. The command line arguments are identical to assignment 1 but with the stage being 3 instead.
The first argument will be the stage, for this part, the value will always be
3(for linked list lookup with comparison count added).The second argument will be the name of the input CSV data file.
The third argument will be the name of the output file.
Your dict3 program should function exactly the same as assignment 1's stage 1. You will add the functionality to count comparisons when searching for a key which will be added to the stdout output. For this stage, and this stage only, you may assume:
Each character compared adds exactly 8 bits to the bit comparison count.
The node access is incremented once per accessed linked list node.
Each string comparison, even if a mismatch occurs on the first character, is 1 string comparison.
You should create the functionality to store comparisons with stage 4 in mind. You will also be recording comparisons in the Patricia tree implementation, so your code should be easily applied to both. For this reason, you may want to extend your search function to include a pointer to a struct that holds information about the query and results.
Important Notes:
You do not have to implement any spellchecking in the linked list. Your only task at this stage is to add functionality to count comparisons.
You do not need to add this functionality to the deletion of nodes. Only the search will be assessed. You should, however, be able to recognize how to implement this in your deletion code.
Example Execution

Example Output
The expected output to the output file would look like:
With the following printed to stdout:
Note: the bit comparisons are 8 times the character comparisons here
Stage 4: Patricia Tree Spellchecker
In Stage 4, you will implement the another dictionary allowing the lookup of data by key (Suburb Name).
Your Makefile should produce an executable program called dict4. This program should take three command line arguments:
The first argument will be the stage, for this part, the value will always be 4 (for Patricia tree lookup and comparison counting).
The second argument will be the name of the input CSV data file.
The third argument will be the name of the output file.
Your dict4 program should:
Read the data in the same format as assignment 1 and stage 1, and save each entry in a Patricia tree using the Official Name Suburb as the key.
The program should:
Accept
Official Name Suburbs fromstdin, and search the tree for the matching key. Since your program should act as a simple spellchecker, an exact match may not be found. Follow the process "mismatch in key" as outlined below to implement spellchecking logic.You must output all matching records to the output file, where a matching record may be an exact match, or the closest match determined by the mismatch key algorithm. If no matches for the query are found (i.e. the trie is empty), your program should output
NOTFOUND. When outputting data records, you should follow the guidelines described in the slide Dataset and Assumptions.In addition to outputting the record(s) to the output file, the number of records found and the comparisons and node accesses when querying should be output to
stdout.
Mismatch in Key
Since a Patricia tree is a type of prefix tree, any mismatch that occurs will contain the same prefix. For example, say we are searching for "trie", but our dictionary contains "tree". Here, a mismatch occurs at some binary bit in the third character. This mismatch will only occur once we are past the node in our tree that contains all prefixes with "tr". Therefore, when the mismatch occurs, we can get all descendants at the mismatched node and calculate the most likely candidate using the edit distance of the query and a key. This way, if we query "trie", we should return "tree". This is explained with the following graphic:
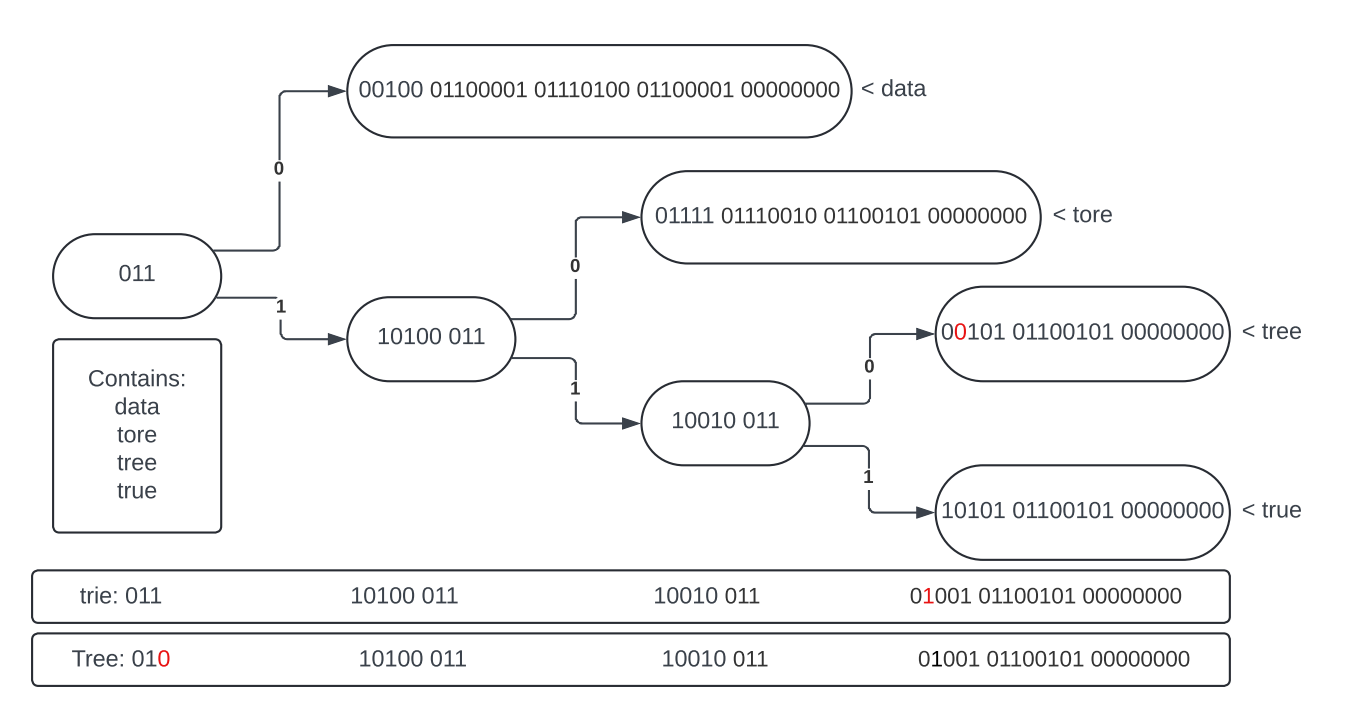
The patricia tree contains 4 strings as listed. If we query "trie", the mismatch happens on the bit highlighted in red. At this node, the only descendant data is "tree", and is therefore determined to be the closest match.
If we query "Tree", the mismatch happens on the third bit. This means that all descendant data is taken to be possible candidates, so all 4 keys have their edit distance against the query calculated. "tree" is determined to be the closest match with an edit distance of 1, and is returned.
Implementation Requirements
The implementation requirements are broadly the same as for Assignment 1. Though the data structure requirements differ slightly. The comparison count matching requirements are also slightly varied to reflect differences in counting that may be equally sensible to the recommended counting method.
The following implementation requirements must be adhered to:
Programming Language: You must write your code in the C programming language.
Record Structure: Each data record (representing a suburb) must be stored in a custom structure (
struct) that reflects the previously mentioned data types. This struct will have member variables for each field (Year, Suburb Code, etc.) with the appropriate data types (int, double, string).Linked List Implementation: You must use a linked list to implement the dictionary in Stage 3. The order in which data records appear in the input file must be preserved within the linked list.
Patricia Tree Implementation: You must use a Patricia tree to implement the dictionary in Stage 4. The order in which data records appear in the input file must be preserved within the Patricia tree (i.e. duplicates should appear in the same order as the relative order in the original file).
Modular Design: You must write your code in a modular way. This means your dictionary operations should be kept together in a separate
.cfile, with its own header.hfile, separate from the main program. Other distinct modules should similarly be separated into their own sections, requiring as little knowledge of each other's internal details as possible. This facilitates easier use in other programs without extensive rewriting or copying.Multiple Dictionary Support: Your code should be easily extensible to handle multiple dictionaries. The functions for interacting with your dictionary should take arguments that include not only the values required for the operation but also a pointer to a specific dictionary (e.g.,
search(dictionary, value)).Single File Read: Your implementation must read the input file only once.
Space-Efficient Strings: Your program should store strings in a space-efficient manner. If you use
malloc()to allocate space for a string, remember to allocate enough space for the final end-of-string character (\0).Exact Output Matching: Your outputs for sample tests should be exactly identical to the expected output, including the order in which the data appears. This means your program's results must match the provided test cases character-for-character, preserving the order of elements within the output. Your comparison counts are not required to match the provided test cases, but you should understand and note why these do not match by noting how you count these if you do not match the provided test cases.
Makefile: A fullMakefileis not provided. TheMakefileshould direct the compilation of your program. To use it, ensure it's in the same directory as your code. Typemake dict3to build the first program andmake dict4to make the second program. You must submit yourMakefilewith your assignment.